OKEP-5296: OVN-Kubernetes BGP Integration¶
- Issue: #5296
Networking Glossary¶
| Term | Definition |
|---|---|
| BGP (Border Gateway Protocol) | A standardized exterior gateway protocol used to exchange routing and reachability information between autonomous systems (ASes) on the Internet. BGP makes routing decisions based on path attributes and policies. |
| BGPd | A daemon (background service) that implements the BGP protocol, commonly found in routing software suites like FRRouting (FRR) or Quagga. It manages BGP sessions, route advertisements, and policy enforcement. |
| BFD (Bidirectional Forwarding Detection) | A network protocol that quickly detects faults in the path between two forwarding devices. It enables sub-second failure detection, often used with BGP or OSPF for faster convergence. |
| iBGP (Internal BGP) | A BGP session between routers within the same autonomous system (AS). It is used to distribute external routes internally, usually requiring a full mesh or route reflectors. |
| eBGP (External BGP) | A BGP session between routers in different autonomous systems. It is the primary method for routing between networks on the Internet. |
| OSPF (Open Shortest Path First) | A link-state interior gateway protocol (IGP) used to distribute IP routing information within a single autonomous system. It calculates the shortest path to each destination using Dijkstra's algorithm and converges quickly. |
Problem Statement¶
OVN-Kubernetes currently has no native routing protocol integration, and relies on a Geneve overlay for east/west traffic, as well as third party operators to handle external network integration into the cluster. The purpose of this enhancement is to introduce BGP as a supported routing protocol with OVN-Kubernetes. The extent of this support will allow OVN-Kubernetes to integrate into different BGP user environments, enabling it to dynamically expose cluster scoped network entities into a provider’s network, as well as program BGP learned routes from the provider’s network into OVN.
Goals¶
- To provide a user facing API to allow configuration of iBGP or eBGP peers, along typical BGP configuration including communities, route filtering, etc.
- Support for advertising Egress IP addresses.
- To enable BFD to BGP peers.
- To allow east/west traffic without encapsulation.
- ECMP routing support within OVN for BGP learned routes.
- Support for advertising user-defined networks via BGP as long as there is no subnet overlap over the default VRF.
- Allowing for VRF-Lite type of VPN where the user maps interfaces on the host to user-defined VRFs/networks and advertises VPN routes via BGP sessions over said VRFs.
Non-Goals¶
- Running separate BGPd instances per VRF network.
- Providing any type of API or operator to automatically connect two Kubernetes clusters via L3VPN.
- Replacing the support that MetalLB provides today for advertising service IPs.
- Support for any other type of BGP speaker other than FRR.
Future Goals¶
- Support EVPN configuration and integration with a user’s DC fabric, along with MAC-VRFs and IP-VRFs.
- Support iBGP with route reflectors.
- Potentially advertising other IP addresses, including the Kubernetes API VIP across the BGP fabric.
- Optimize Layer 2 network routing.
- Allow selecting only a subset of nodes to advertise BGP.
- Support other routing protocols like OSPF.
- Support disabling Geneve as an overlay transport and either using a pure routed, no-overlay topology as well as an EVPN VXLAN overlay.
Introduction¶
There are multiple driving factors which necessitate integrating BGP into OVN-Kubernetes. They will be broken down into sections below, describing each use case/requirement. Additionally, implementing BGP paves the way for full EVPN support in the future, which is the choice of networking fabric in the modern data center. For purposes of this document, the external, physical network of the cluster which a user administers will be called the “provider network”.
Importing Routes from the Provider Network¶
Today there is no API for a user to be able to configure routes into OVN. In order for a user to change how egress traffic is routed, the user leverages local gateway mode. This mode forces traffic to hop through the Linux networking stack, and there a user can configure routes inside of the host via NM State to control egress routing. This manual configuration would need to be performed and maintained across nodes and VRFs within each node.
Additionally, if a user chooses to not manage routes within the host for local gateway mode, or the user chooses shared gateway mode, then by default traffic is always sent to the default gateway. The only other way to affect egress routing is by using the Multiple External Gateways (MEG) feature. With this feature the user may choose to have multiple different egress gateways per namespace to send traffic to.
As an alternative, configuring BGP peers and which route-targets to import would eliminate the need to manually configure routes in the host, and would allow dynamic routing updates based on changes in the provider’s network.
Exporting Routes into the Provider Network¶
There exists a need for provider networks to learn routes directly to services and pods today in Kubernetes. More specifically, MetalLB is already one solution where load balancer IPs are advertised by BGP to provider networks. The goal of this RFE is to not duplicate or replace the function of MetalLB. MetalLB should be able to interoperate with OVN-Kubernetes, and be responsible for advertising services to a provider’s network.
However, there is an alternative need to advertise pod IPs on the provider network. One use case is integration with 3rd party load balancers, where they terminate a load balancer and then send packets directly to OCP nodes with the destination IP address being the pod IP itself. Today these load balancers rely on custom operators to detect which node a pod is scheduled to and then add routes into its load balancer to send the packet to the right node.
By integrating BGP and advertising the pod subnets/addresses directly on the provider network, load balancers and other entities on the network would be able to reach the pod IPs directly.
Datapath Performance¶
In cases where throughput is a priority, using the underlay directly can eliminate the need for tunnel encapsulation, and thus reducing the overhead and byte size of each packet. This allows for greater throughput.
Multi-homing, Link Redundancy, Fast Convergence¶
BGP can use multi-homing with ECMP routing in order to provide layer 3 failover. When a link goes down, BGP can reroute via a different path. This functionality can be coupled with BFD in order to provide fast failover. A typical use case is in a spine and leaf topology, where a node has multiple NICs for redundancy that connect to different BGP routers in topology. In this case if a link goes down to one BGP peer or the BGP peer fails, BFD can detect the outage on the order of milliseconds to hundreds of milliseconds and quickly assist BGP in purging the routes to that failed peer. This then causes fast failover and route convergence to the alternate peer.
User-Stories/Use-Cases¶
- As a user I want to be able to leverage my existing BGP network to dynamically learn routes to pods in my Kubernetes cluster.
- As a user, rather than having to maintain routes with NM State manually in each Kubernetes node, as well as being constrained to using local gateway mode for respecting user defined routes; I want to use BGP so that I can dynamically advertise egress routes for the Kubernetes pod traffic in either gateway mode.
- As a user where maximum throughput is a priority, I want to reduce packet overhead by not having to encapsulate traffic with Geneve.
- As an egress IP user, I do not want to have to restrict my nodes to the same layer 2 segment and prefer to use a pure routing implementation to handle advertising egress IP movement across nodes.
Proposed Solution¶
OVN-Kubernetes will leverage other CNCF projects that already exist to enable BGP in Linux. FRR will be used as the BGP speaker, as well as provide support for other protocols like BFD. For FRR configuration, the MetalLB project has already started an API to be able to configure FRR: https://github.com/metallb/frr-k8s. While some of the configuration support for FRR may be directly exposed by FRR-K8S API, it may also be the case that some intermediary CRD provided by OVN-Kubernetes is required to integrate OVN-Kubernetes networking concepts into FRR.
Functionally, FRR will handle advertising and importing routes and configuring those inside a Linux VRF. OVN-Kubernetes will be responsible for listening on netlink and configuring logical routers in OVN with routes learned by FRR. OVN-Kubernetes will manage FRR configuration through the FRR-K8S API in order to advertise routes outside of the node onto the provider network.
There should be no changes required in FRR. FRR-K8S may need extended APIs to cover the OVN-Kubernetes use cases proposed in this enhancement. The lifecycle management of FRR-K8S and FRR is outside the scope of this enhancement and will not be managed by OVN-Kubernetes.
OVN will require no changes.
Workflow Description¶
An admin has the ability to configure BGP peering and choose what networks to advertise. A tenant is able to define networks for their namespace, but requires admin permission in order to expose those networks onto the provider's BGP fabric. A typical workflow will be for a user or admin to create a user-defined network, and then the admin will be responsible to:
- If setting up VRF-Lite, do any host modifications necessary via NMState to enslave an IP interface to the matching network VRF.
- Configure BGP peering via interacting with the FRR-K8S API for a given set of worker nodes. Also define filters for what routes should be received from the provider network.
- Create the OVN-Kubernetes RouteAdvertisements CR to configure what routes and where to advertise them.
- Verify peering and that routes have been propagated correctly.
For detailed examples, see the BGP Configuration section.
API Extensions¶
FRR-K8S API will be used in order to create BGP Peering and configure other BGP related configuration. A RouteAdvertisements CRD will be introduced in order to determine which routes should be advertised for specific networks. Additionally, the network CRD will be modified in order to expose a new transport field to determine if encapsulation should be used for east/west traffic.
API Details¶
Route Advertisements¶
When OVN-Kubernetes detects that a FRR-K8S CR has been created for BGP peering, OVN-Kubernetes will by default advertise the pod subnet for each node, via creating an additive, per node FRR-K8S CR that is managed by OVN-Kubernetes. OVN-Kubernetes CRD:
apiVersion: k8s.ovn.org/v1
kind: RouteAdvertisements
metadata:
name: default
spec:
nodeSelector: {}
frrConfigurationSelector: {}
networkSelectors:
- networkSelectionType: ClusterUserDefinedNetworks
clusterUserDefinedNetworkSelector:
networkSelector:
matchLabels:
bgp: "enabled"
targetVRF: default
advertisements:
- PodNetwork
- EgressIP
In the above example, a required networkSelector field is populated to match on CUDNs matching the shown label. Alternatively, a user may specify the DefaultNetwork as the networkSelectionType. If a selector is used that selects the default cluster network, it will be enabled for any namespace using the cluster default network. Additionally, advertisements may be limited to specific nodes via the nodeSelector.
In the case where a CUDN network selector is used, the networks will be checked by OVN-Kubernetes to determine if there is any overlap of the IP subnets. If so, an error status will be reported to the CRD and no BGP configuration will be done by OVN-Kubernetes.
Multiple CRs may not select the same network. If this happens OVN-Kubernetes will report an error to the RouteAdvertisements CR and will refuse to apply the config.
The CRD will support enabling advertisements for pod subnet and egress IPs. Note, MetalLB still handles advertising LoadBalancer IP so there is no conflict of responsibilities here. When the pod network is set to be advertised, there is no longer a need to SNAT pod IPs for this network to the node IP. Therefore, when pod network advertisements are enabled, the traffic from these pods will no longer be SNAT'ed on egress.
The "targetVRF" key is used to determine which VRF the routes should be advertised in. The default value is "default", in which case routes will be leaked into the default VRF. One use case for this would be when a user wants to define a network with a specific IP addressing scheme, and then wants to advertise the pod IPs into the provider BGP network without VPN. Note that by using route leaking with a user-defined network, the network is no longer fully isolated, as now any other networks also leaked or attached to that VRF may reach this user-defined network. If a user attempts to leak routes into a targetVRF for a user-defined network whose IP subnet would collide with another, OVN-Kubernetes will report an error to the RouteAdvertisement status. Alternatively, a user may specify the value "auto", which in which case OVN-Kubernetes will advertise routes in the VRF that corresponds to the selected network. Any other values other than "auto" or "default" will result in an error. There is no support at this time for routing leaking into any other VRF.
The frrConfigurationSelector is used in order to determine which FRRConfiguration CR to use for building the OVN-Kubernetes driven FRRConfiguration. OVN-Kubernetes needs to leverage a pre-existing FRRConfiguration to be able to find required pieces of configuration like BGP peering, etc. If more than one FRRConfiguration is found matching the selector, then an error will be propagated to the RouteAdvertisements CR and no configuration shall be done.
Implementation Details¶
BGP Configuration¶
When OVN-Kubernetes detects that a FRRConfiguration has been created that has a corresponding and valid FRRNodeState, OVN-Kubernetes will then use RouteAdvertisements CR create a corresponding FRRConfiguration. The following examples will use an environment where a user has created an FRRConfiguration:
apiVersion: frrk8s.metallb.io/v1beta1
kind: FRRConfiguration
metadata:
creationTimestamp: "2024-06-11T14:22:37Z"
generation: 1
name: metallb-ovn-worker
namespace: metallb-system
resourceVersion: "1323"
uid: 99b64be3-4f36-4e0b-8704-75aa5182d89f
labels:
routeAdvertisements: default
spec:
bgp:
routers:
- asn: 64512
neighbors:
- address: 172.18.0.5
asn: 64512
disableMP: false
holdTime: 1m30s
keepaliveTime: 30s
passwordSecret: {}
port: 179
toAdvertise:
allowed:
mode: filtered
toReceive:
allowed:
mode: filtered
nodeSelector:
matchLabels:
kubernetes.io/hostname: ovn-worker
ovnkube-controller will check that if this FRRConfiguration applies to its node, ovn-worker. For this example, a user-defined network named "blue", has been created with a network of 10.0.0.0/16, and a matching vrf exists in the Linux host. The slice of this supernet that has been allocated to node ovn-worker is 10.0.1.0/24.
Example 1: Advertising pod IPs from a user-defined network over BGP¶
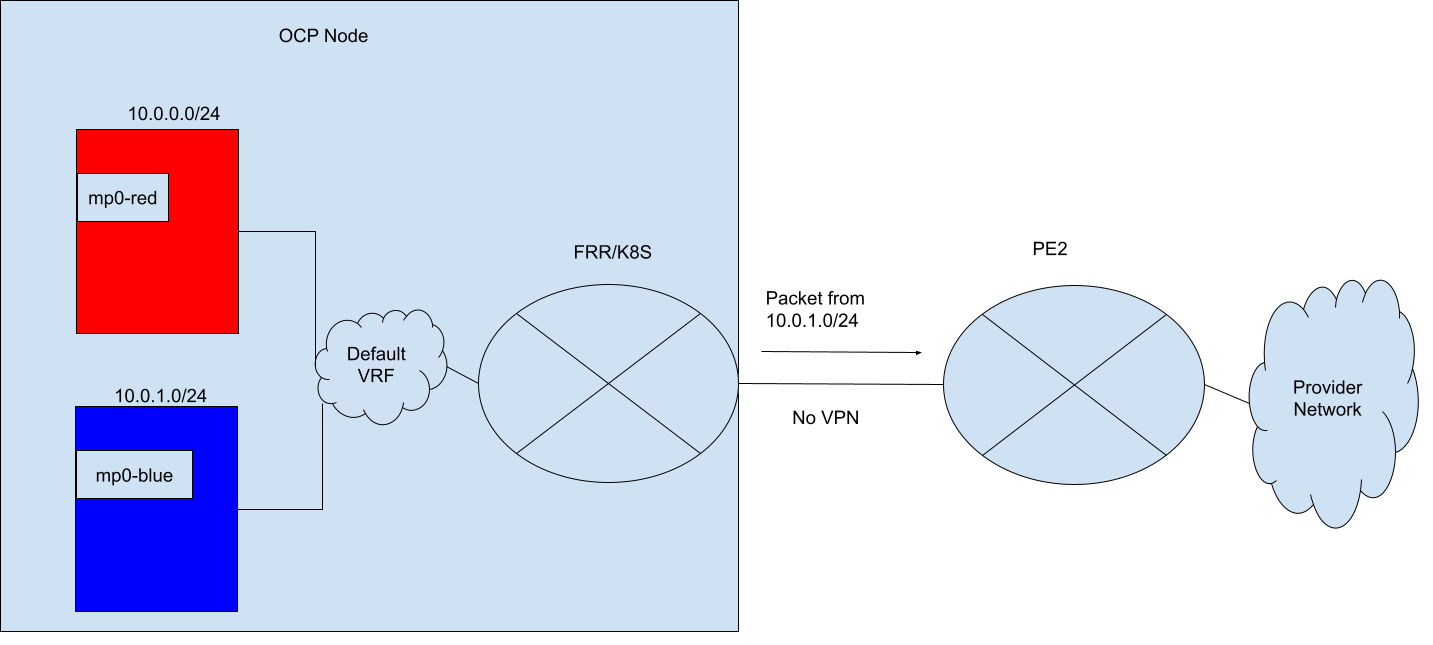
In this example a user wants to expose network blue outside their OCP cluster so that pod IPs are reachable on the external network. The admin has creates the following RouteAdvertisements CR for the blue tenant:
apiVersion: k8s.ovn.org/v1
kind: RouteAdvertisements
metadata:
name: default
spec:
advertisements:
podNetwork: true
networkSelector:
matchLabels:
k8s.ovn.org/metadata.name: blue
nodeSelector:
matchLabels:
kubernetes.io/hostname: ovn-worker
frrConfigurationSelector:
matchLabels:
routeAdvertisements: default
ovnkube-controller will now see it needs to generate corresponding FRRConfiguration:
apiVersion: frrk8s.metallb.io/v1beta1
kind: FRRConfiguration
metadata:
name: route-advertisements-blue
namespace: metallb-system
spec:
bgp:
routers:
- asn: 64512
vrf: blue
prefixes:
- 10.0.1.0/24
- asn: 64512
neighbors:
- address: 172.18.0.5
asn: 64512
toAdvertise:
allowed:
prefixes:
- 10.0.1.0/24
raw:
rawConfig: |-
router bgp 64512
address-family ipv4 unicast
import vrf blue
exit-address-family
router bgp 64512 vrf blue
address-family ipv4 unicast
import vrf default
exit-address-family
nodeSelector:
matchLabels:
kubernetes.io/hostname: ovn-worker
In the above configuration generated by OVN-Kubernetes, the subnet 10.0.1.0/24 which belongs to VRF blue, is being imported into the default VRF, and advertised to the 172.18.0.5 neighbor. This is because the targetVRF was defaulted so the routes are leaked and advertised in the default VRF. Additionally, routes are being imported from the default VRF into the blue VRF. At the time of this writing, FRR-K8S does not support importing vrf routes as an API, and thus rawConfig is used. However, when implementing this enhancement every attempt should be made to add support into FRR-K8S to use its API rather than using rawConfig.
Example 2: VRF Lite - Advertising pod IPs from a user-defined network over BGP with VPN¶
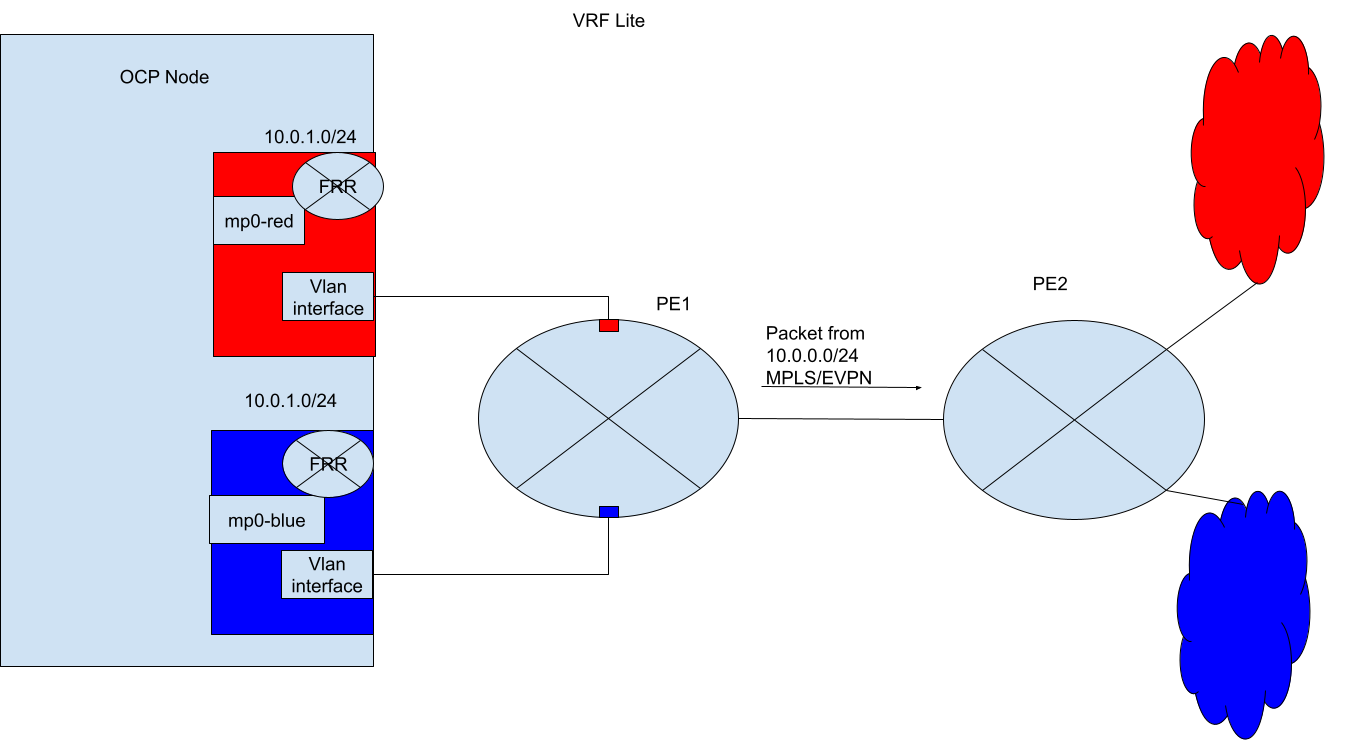
In this example, the user provisions a VLAN interface, enslaved to the VRF, which carries the blue network in isolation to the external PE router. This provides a VRF-Lite design where FRR-K8S is going to be leveraged to advertise the blue network only over the corresponding VRF/VLAN link to the next hop PE router. The same is done for the red tenant. Here the user has created an additional FRRConfiguration CR to peer with the PE router on the blue and red VLANs:
apiVersion: frrk8s.metallb.io/v1beta1
kind: FRRConfiguration
metadata:
name: vpn-ovn-worker
namespace: metallb-system
labels:
routeAdvertisements: vpn-blue-red
spec:
bgp:
routers:
- asn: 64512
vrf: blue
neighbors:
- address: 182.18.0.5
asn: 64512
disableMP: false
holdTime: 1m30s
keepaliveTime: 30s
passwordSecret: {}
port: 179
toAdvertise:
allowed:
mode: filtered
toReceive:
allowed:
mode: filtered
- asn: 64512
vrf: red
neighbors:
- address: 192.18.0.5
asn: 64512
disableMP: false
holdTime: 1m30s
keepaliveTime: 30s
passwordSecret: {}
port: 179
toAdvertise:
allowed:
mode: filtered
toReceive:
allowed:
mode: filtered
The admin now creates the following RouteAdvertisements CR:
apiVersion: k8s.ovn.org/v1
kind: RouteAdvertisements
metadata:
name: default
spec:
targetVRF: auto
advertisements:
podNetwork: true
networkSelector:
matchExpressions:
- { key: k8s.ovn.org/metadata.name, operator: In, values: [blue,red] }
nodeSelector:
matchLabels:
kubernetes.io/hostname: ovn-worker
frrConfigurationSelector:
matchLabels:
routeAdvertisements: vpn-blue-red
In the above CR, the targetVRF is set to auto, meaning the advertisements will occur within the VRF corresponding to the individual networks selected. In this case, the pod subnet for blue will be advertised over the blue VRF, while the pod subnet for red will be advertised over the red VRF. OVN-Kubernetes creates the following FRRConfiguration:
apiVersion: frrk8s.metallb.io/v1beta1
kind: FRRConfiguration
metadata:
name: route-advertisements-blue
namespace: metallb-system
spec:
bgp:
routers:
- asn: 64512
neighbors:
- address: 182.18.0.5
asn: 64512
toAdvertise:
allowed:
prefixes:
- 10.0.1.0/24
vrf: blue
prefixes:
- 10.0.1.0/24
- asn: 64512
neighbors:
- address: 192.18.0.5
asn: 64512
toAdvertise:
allowed:
prefixes:
- 10.0.1.0/24
vrf: red
prefixes:
- 10.0.1.0/24
nodeSelector:
matchLabels:
kubernetes.io/hostname: ovn-worker
OVN-Kubernetes uses the configuration already in place in FRR and the desired RouteAdvertisements to generate the above FRRConfiguration. For filtering or choosing what routes to receive, a user should do that in the FRRConfiguration they declare for peering.
Note, VRF-Lite is only available when using Local Gateway Mode in OVN-Kubernetes.
Preserving UDN Isolation¶
By definition, UDNs are expected to provide network isolation. With the ability to advertise UDNs within the same BGP VRF, it opens the door for users on one UDN to try to access another UDN via external routing. This may be undesirable for users who are simply exposing their UDN onto a VRF to allow direct ingress to those pods from outside the cluster, and not necessarily wanting to allow UDNs to communicate. Therefore by default, access between externally routed UDNs will be blocked by ACLs internal to OVN. This will protect users from accidentally exposing their UDNs to other tenants.
In the future, an option will be added to allow a cluster admin to specify that UDNs exposed via BGP may be externally routed between each other. Note, this security limitation only applies to pod and cluster IP service addresses . If a group of pods is exposed externally as service (LoadBalancer, NodePort, External IP), then external routing from another UDN will succeed. This is by design as the user has explicitly opened their service up to the outside world.
Additionally, when Kubernetes nodes are directly peered with each other and not an external provider BGP router, remote node UDN subnets are not imported in order to prevent issues with isolation, as well as issues with accidentally routing via the underlay for a UDN pod subnet.
BGP Route Advertisements¶
Layer 3 Topology¶
With a Layer 3 network type, each BGP node should advertise the node subnet assigned to it. Since the cluster supernet is divided into per node subnets, it makes sense to advertise those from each node. This will result in direct routing to the node that hosts destination pod. In the future when nodeSelector is supported, all BGP speakers will also need to advertise the cluster supernet. This will allow ECMP routes via any BGP enabled node for reachability to nodes not participating in BGP.
Layer 2 Topology¶
Layer 2 networks are more complicated than Layer 3 due to the nature of a single subnet spanning multiple nodes. In other words the cluster supernet is not subnetted out on a per-node basis. Therefore, every node must advertise the cluster supernet. This results in asynchronous routing, and in practical terms, packets having to endure an extra hop before making it to their destination node. This can result in reply traffic hitting different nodes, and thus conntrack is unreliable. With OVN, Logical Switches will by default drop packets that are CT_INVALID (Logical Routers do not behave this way) and thus the OVN will need to be configured to not drop CT_INVALID packets by setting:
ovn-nbctl set NB_Global . options:use_ct_inv_match=false
In the future, routing optimizations will be implemented which break up contiguous address blocks of the supernet to each node for assignment. This will be similar to how Layer 3 subnetting works, except there will not be individual subnets, but ranges instead. With this design, each node can advertise their contiguous range as well as the supernet. For example with a supernet of 10.244.0.0/16, a node A may be assigned a block of 256 addresses (10.244.0.0/24). In this case node A would advertise both 10.244.0.0/16 and 10.244.0.0.0/24 routes. This will result in direct routing for pods.
Additionally, VMs may migrate on Layer 2 networks. In, which case the VM pod on node A with an address of 10.244.0.5 may migrate to node B. With the existing route advertisement scheme, traffic destined to this VM would first route towards node A and then to node B. To resolve this, when a VM migrates to a node, a /32 route will be advertised from the target node. So node B would advertise (in order of longest prefix): - 10.244.0.5/32 - 10.244.1.0/24 - 10.244.0.0/16
As a VM migrates back to another node or back to its original node, the /32 route will be removed.
Egress IP¶
Egress IP will be advertised at the node where the Egress IP is assigned as a /32 route. If the Egress IP migrates to a different node, then the new node will be responsible for advertising the Egress IP route. Egress IPs advertised via BGP must share the same nodeSelector in the Egress IP resource and the RouteAdvertisement resource to function correctly.
Feature Compatibility¶
Multiple External Gateways (MEG)¶
When using BGP to learn routes to next hops, there can be overlap with gateways detected by the MEG feature. MEG may still be configured along with BFD in OVN, and overlapping routes learned from BGP will be ignored by OVN-Kubernetes. BFD may also be configured in FRR, for immediate purging of learned routes by FRR.
A user can also configure RouteAdvertisements for namespaces affected by MEG. Since MEG directly uses pod IPs (in disable-snat-multiple-gws mode), the external gateway needs to know where to route pod IPs for ingress and egress reply traffic. Traditionally this is done by the gateway having its own operator to detect pod subnets via kubernetes API. With BGP, this is no longer necessary. A user can simply configure RouteAdvertisements, and the pod subnet routes will be dynamically learned by an external gateway capable of BGP peering.
Egress IP¶
EgressIP feature that is dynamically moved between nodes. By enabling the feature in RouteAdvertisements, OVN-Kubernetes will automatically change FRR-K8S configuration so that the node where an egress IP resides will advertise the IP. This eliminates the need for nodes to be on the same layer 2 segment, as we no longer have to rely on gratuitous ARP (GARP).
Services¶
MetalLB will still be used in order to advertise services across the BGP fabric.
Egress Service¶
Full support.
Egress Firewall¶
Full support.
Egress QoS¶
Full Support.
Network Policy/ANP¶
Full Support.
Direct Pod Ingress¶
Direct pod ingress is already enabled for the default cluster network. With direct pod ingress, any external entity can talk to a pod IP if it sends the packet to the node where the pod lives. Previously, support for direct pod ingress on user-defined networks was not supported. RouteAdvertisements with this enhancement may select user-defined networks and enable pod network advertisements. Therefore, it only makes sense to also accept direct pod ingress for these user-defined networks as well, especially since we know the selected subnets will not overlap in IP address space.
Ingress via OVS bridge¶
Modifications will need to be made so that for packets arriving on br-ex, flows are added to steer the selected pod subnets to the right OVN GR patch port. Today the flow for the default cluster network looks like this:
[root@ovn-worker ~]# ovs-ofctl show breth0
OFPT_FEATURES_REPLY (xid=0x2): dpid:00000242ac120003
n_tables:254, n_buffers:0
capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP
actions: output enqueue set_vlan_vid set_vlan_pcp strip_vlan mod_dl_src mod_dl_dst mod_nw_src mod_nw_dst mod_nw_tos mod_tp_src mod_tp_dst
1(eth0): addr:02:42:ac:12:00:03
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
2(patch-breth0_ov): addr:ca:2c:82:e9:06:42
config: 0
state: 0
speed: 0 Mbps now, 0 Mbps max
[root@ovn-worker ~]# ovs-ofctl dump-flows breth0 |grep 10.244
cookie=0xdeff105, duration=437.393s, table=0, n_packets=4, n_bytes=392, idle_age=228, priority=109,ip,in_port=2,dl_src=02:42:ac:12:00:03,nw_src=10.244.1.0/24 actions=ct(commit,zone=64000,exec(load:0x1->NXM_NX_CT_MARK[])),output:1
cookie=0xdeff105, duration=437.393s, table=0, n_packets=0, n_bytes=0, idle_age=437, priority=104,ip,in_port=2,nw_src=10.244.0.0/16 actions=drop
cookie=0xdeff105, duration=437.393s, table=1, n_packets=4, n_bytes=392, idle_age=228, priority=15,ip,nw_dst=10.244.0.0/16 actions=output:2
Packets matching the pod IP are forwarded directly to OVN, where they are forwarded to the pod without SNAT. Additional flows will need to be created for additional networks. For shared gateway mode, the reply packet will always return via OVS and follow a symmetrical path. This is also true if local gateway mode is being used in combination with Multiple External Gateways (MEG). However, if local gateway mode is used without MEG, then the reply packet will be forwarded into the kernel networking stack, where it will routed out br-ex via the kernel routing table.
Ingress via a Secondary NIC¶
If packets enter into the host via a NIC that is not attached to OVS, the kernel networking stack will forward it into the proper VRF, where it will be forwarded via ovn-k8s-mp0 of the respective user-defined network. Today when these packets ingress ovn-k8s-mp0 into OVN, they are SNAT'ed to the ovn-k8s-mp0 address (.2 address). Reasons for this include: 1. To ensure incoming traffic that may be routed to another node via geneve would return back to this node. This is undesirable and unnecessary for networks where only their respective per-node pod subnet is being advertised to the BGP fabric. 2. If running shared gateway mode, the reply packet would be routed via br-ex with the default gateway configured in ovn_cluster_router.
For local gateway mode, changes will need to be made to skip the SNAT as it is not necessary and provides pods with the true source IP of the sender.
Additionally, modifications will need to be made in the kernel routing table to leak routes to the pod subnets from each user-defined VRF into the default VRF routing table.
Testing Details¶
- E2E upstream with a framework (potentially containerlab.dev to simulate a routed spine and leaf topology with integration using OVN-Kubernetes.
- Testing using transport none for some networks, and Geneve for non-BGP enabled networks.
- Testing to cover BGP functionality including MEG, Egress IP, Egress QoS, etc.
- Scale testing to determine impact of FRR-K8S footprint on large scale deployments.
Documentation Details¶
- ovn-kubernetes.io will be updated with a BGP user guide
- Additional dev guides will be added to the repo to show how the internal design of BGP is implemented.
Risks, Known Limitations and Mitigations¶
Using BGP, especially for east/west transport relies on the user's BGP network. Therefore, BGP control plane outages in a user's network may impact cluster networking. Furthermore, when changing a network's transport there will be some amount of traffic disruption. Finally, this entire feature will depend on correct BGP peering via FRR-K8S configuration, as well as settings to match the proper communities, route filtering, and other BGP configuration within the provider's BGP network.
In addition, by dynamically learning routes and programming them into OVN, we risk a customer accidentally introducing potentially hundreds or even thousands of routes into different OVN logical routers. As a mitigation, we can recommend using communities or route aggregation to customers to limit RIB size. We will also need to scale test the effect of many routes inside OVN logical routers.
Another risk is integration with MetalLB. We need to ensure that MetalLB is still able to function correctly with whatever OVN-Kubernetes is configuring within FRR.
BGP has a wide range of configurations and configuration options that are supported by FRR today. There is a big risk of scope creep to try to support all of these options during the initial development phase. During the initial release the number of options supported will be limited to mitigate this issue, and the main focus will be on stability of a default environment without enabling these extra options/features.
Reliance on FRR is another minor risk, with no presence from the OVN-Kubernetes team involved in that project.
OVN-Kubernetes Version Skew¶
BGP will be delivered in version 1.1.0.
Alternatives¶
None
References¶
None